Part 2: Couchbase architecture in a Nutshell
Distributed & scalable by design & easy development
Couchbase has been built from the ground up to be a distributed database with easy scalability and management features for IT operations. Furthermore, it provides easy development, because developers don’t need to care about cluster topology and how data is distributed. Through the use of smart client SDKs (drivers) they can automatically access data in 4 ways:
- Simple Key Value CRUD operations
- ANSI compliant SQL queries
- Incremental map-reduce Views queries
- Couchbase Full Text Search (developer preview at time of writing this blog)
This blog aims to explain why Couchbase is so easy to use for both developers and DBA operation teams.
[
"Questions that might be running through your mind?",
{
"Question #" : 1,
"Developer questions" : [
"how can I access data without caring about data distribution & cluster topology?",
"How does Couchbase distribute data & automatically map queries to the right servers?",
"Are my reads/writes consistent?"
]
},
{
"Question #" : 2,
"Operation/Dev-Op questions" : [
"What makes Couchbase easy to scale?",
"How many server types do I need to deal with?",
"How can I guarantee consistent high performance & avoid hotspots?",
"What about replicas and replica consistency?"
]
}
]Couchbase Single Node Architecture
One of the key reasons why Couchbase is easy to scale is because you don’t need to worry about different server types. There is no concept of master/slave servers, config servers, name nodes etc. There is only one Couchbase server software and therefore one server type. Creating a new Couchbase cluster or scaling out an existing one is very simple:
- spin up a commodity server(s)
- install Couchbase
- add the server(s) to an existing cluster (and rebalance) OR initialize a new cluster
That’s it! No complex configuration files, no external load balancers required and no arduous manual steps. Furthermore, it is an online process; done without code changes to your application, no downtime and no performance impact. So easy that my 8 year old could do it.
Next we delve a little deeper into the single node architecture and discuss two key processes running inside Couchbase Server; the Data and Cluster Managers

The Data manager
This is the user-access path to your data, whether it be KV operations, or View/SQL queries (and future Full text search). Each service (Data, Index and Query) can be enabled or disabled depending on the role you want to assign a Couchbase server. This feature is called Multi Dimensional Scaling (MDS) and it enables you to architect the cluster to suit your needs. More on this later.
It’s also worth mentioning that Couchbase topology changes can be made at runtime without breaking your application. This is possible because Couchbase SDK’s are smart clients, they allow for cluster topology changes at runtime . Simply change the cluster topology without any code changes or application restarts. Furthermore, Couchbase smart clients automatically route KV operations, View, SQL and Full text search queries to the correct Couchbase servers. Therefore MDS and Couchbase smart client technology makes Couchbase both developer and operations friendly.
The Data Service is responsible for storing and retrieving your JSON and binary data using Key Value CRUD operations. Key Value CRUD operations provide the highest throughput and sub-millisecond access to your data. The data service is also responsible for storing local view indexes created using map reduce functions written in JavaScript. View indexes allow querying of data using secondary indexes. You can also use views to perform light weight near real time aggregations (counts, sums, averages etc). Views are stored with the underlying key value data they index. Since Couchbase data is distributed across data service nodes, view indexes are therefore also distributed across all data service nodes.
The Index Service is responsible for Global Secondary Indexes (GSI) that support SQL queries. A key difference between Views and GSI indexes are that views are always distributed across all data service nodes whilst GSI indexes are isolated from the data service and are global (not distributed). It’s important to understand the differences between key/value, view and GSI indexes:
- Couchbase provides Key value data access by automatically routing requests to the correct servers in single network hops. Key value is actually an index (a primary one) architected as an in-memory hash table distributed across all data service enabled servers. Key value provides linear scalability, the best throughput (hundreds of thousands to millions of operations per second) and the lowest latency (<1ms)
- View indexes provide an alternative approach to data access, for those occasions when you don’t know the primary keys for the documents you want to retrieve. Views allow you to access data based on indexed JSON fields. View indexes are local to key value data and hence distributed across all data service nodes. Querying view indexes incurs a scatter-gather overhead, because a query must span across all data-service enabled servers (since each one stores a part of the view index). However updates to view indexes are very fast because they are local to the underlying key value data and updates are made concurrently across all data-service servers.
- GSI indexes also provide an alternative data access path to your document data. The key difference between view and GSI indexes is that GSI indexes are globally stored on single servers (but can be replicated for high availability). Therefore queries underpinned by GSI indexes do not incur the scatter gather overhead. This makes scanning of GSI much faster than views.
Lastly, the Query Service is responsible for serving SQL requests and works in coordination with the Index & Data services. SQL queries can leverage both GSI and view indexes. The query language is ANSI compliant SQL but is extended with additional capabilities that allow you to deal with the unstructured and hierarchal aspects of JSON, for example:
- you can deal with missing or null fields
- you can access embedded JSON data using dot notation
- you can query, nest and unnest collections
The data manager process is written in C/C++ to provide the fastest, most direct and most optimized access path to underlying hardware resources and data. For this reason C based languages are the ideal language of choice for developing high performance and scalable database engines.
Virtual machine (VM) based languages such as Erlang or Java should ideally be avoided when developing high performance database engines, because you don’t have direct access or direct control of memory. As a result VM based database engines are not as performance optimized as C/C++ ones. Also garbage collection may significantly impact database performance whilst running, unless you customize and tune the standard JVMs garbage collection (gc) settings or invest in an enterprise JVM with efficient gc.
The Cluster manager
The cluster manager process allows users to manage and administrate the cluster. It also generates node level and cluster wide statistics for monitoring. This process is written in Erlang because it is an ideal language for building distributed systems. Erlang is a VM based language and for reasons already stated, it is not ideal for developing high performance and scalable database engines (the user-access path to data). For this reason, Erlang is mainly used for cluster management which is not part of the user-access path.
The cluster manager provides a rich web UI for full administrative management and exposes extensive monitoring statistics and graphs. This UI allows you to add/remove servers, create and configure buckets (synonymous to databases), configure cluster-wide options for resource and data management, configure security and a whole lot more.
Interestingly this web UI is underpinned by an extensive admin REST API which is exposed to allow administrators and operations teams to programmatically manage the cluster and monitor statistics. This allows for easy scripting for automated management tasks and easy integration with your SMTP systems. Couchbase also provides extensive command line tools for managing the cluster, performing diagnostics and monitoring stats - all of which are again underpinned by the REST API.
All servers are MASTERS and data access is CONSISTENT
A key difference between Couchbase and many other noSQL databases is that every Couchbase server is a master (there are no slaves) and all data access is to the active data set. This means developers always see consistent data because all requests go to the master data and replica data only exist for high availability.
Since there are no slave server’s, every Couchbase server is actively servicing live requests, whether it be key value CRUD operations or SQL/View queries or maintenance and scanning of indexes. Since every server is dealing with live requests - Couchbase maximizes the utilization of hardware resources.
Furthermore, Couchbase’s total cost of ownership is much lower than other noSQL databases, because it needs far fewer servers for performance and scale. The key reasons for this are:
-
it’s integrated managed cache allows a single server to support extremely high read and write throughput (for read heavy, write heavy or even mixed workloads)
-
every server is responsible for 1/n of workload because Couchbase:
- evenly shards data (no hotspots because the data and therefore workload is effectively load balanced)
- load balances SQL queries and view queries
- and load balances the scanning of GSI indexes (assuming you’ve created the same indexes on more than one index enabled server)
For example, when compared to MongoDB, Couchbase only requires a minimum of 3 servers for a production ready cluster whereas MongoDB best practices dictate 15 servers for production. Here is a great blog detailing this comparison: Setting up a production ready cluster with MongoDB and Couchbase
Multi Dimensional Scaling
The last topic to discuss is Couchbase’s dynamically flexible architecture. The simplest deployment of Couchbase is to enable all services on all Couchbase servers. This effectively stripes all the services across all physical machines. This is fine for small clusters but you may need to consider a different configuration if data volumes or workloads continue to increase.
Fortunately, it’s relatively easy to dynamically re-configure your cluster at runtime. This flexibility is realized through a feature called multi dimensional scaling (MDS), which allows the Couchbase architecture to be changed to suit your data volume and workload needs.
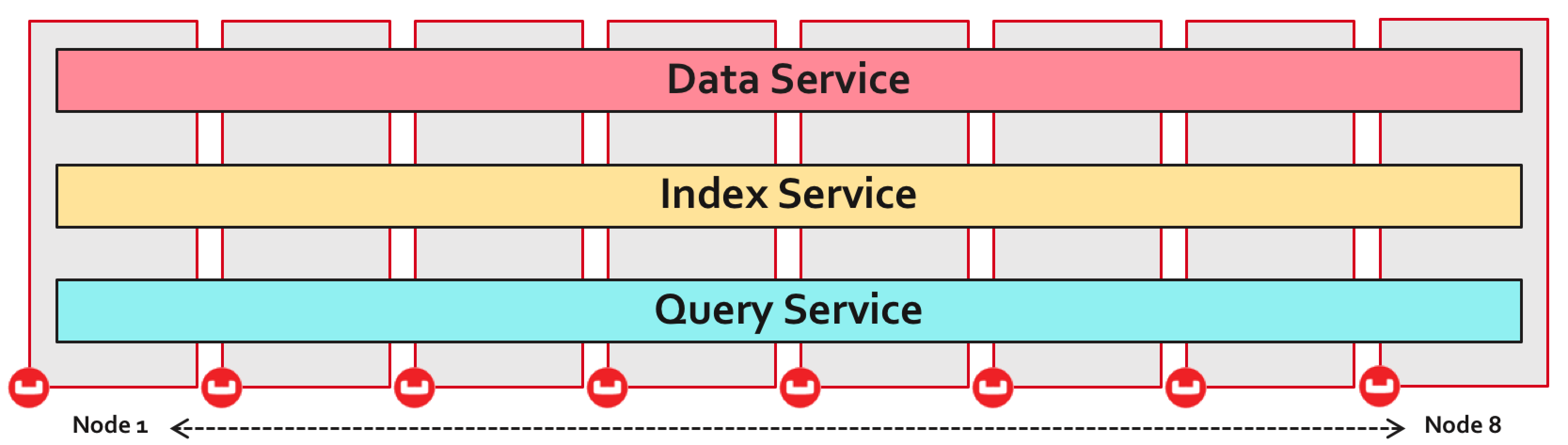
Multi dimensional scaling allows Couchbase to be both scaled OUT & scaled UP. This may seem contradictory - but it makes perfect sense when you want to achieve consistent high performance for all data access paths.
We’ve all heard the hype that scaling out will solve all scaling issues but this is not entirely true. Of course it makes sense to scale out some data access paths namely key value operations - but it doesn’t make sense to scale out when your indexes are distributed across all servers. The more distributed your indexes the greater the scatter gather overhead when scanning them. Therefore, Couchbase allows you to scale out your data service but scale up your index and query services.
Another key advantage of MDS is that it isolates the different data access paths offered by each service and removes any resource contention between them. This makes perfect sense because each service has different hardware resource needs and a single hardware specification would not make sense for all services.
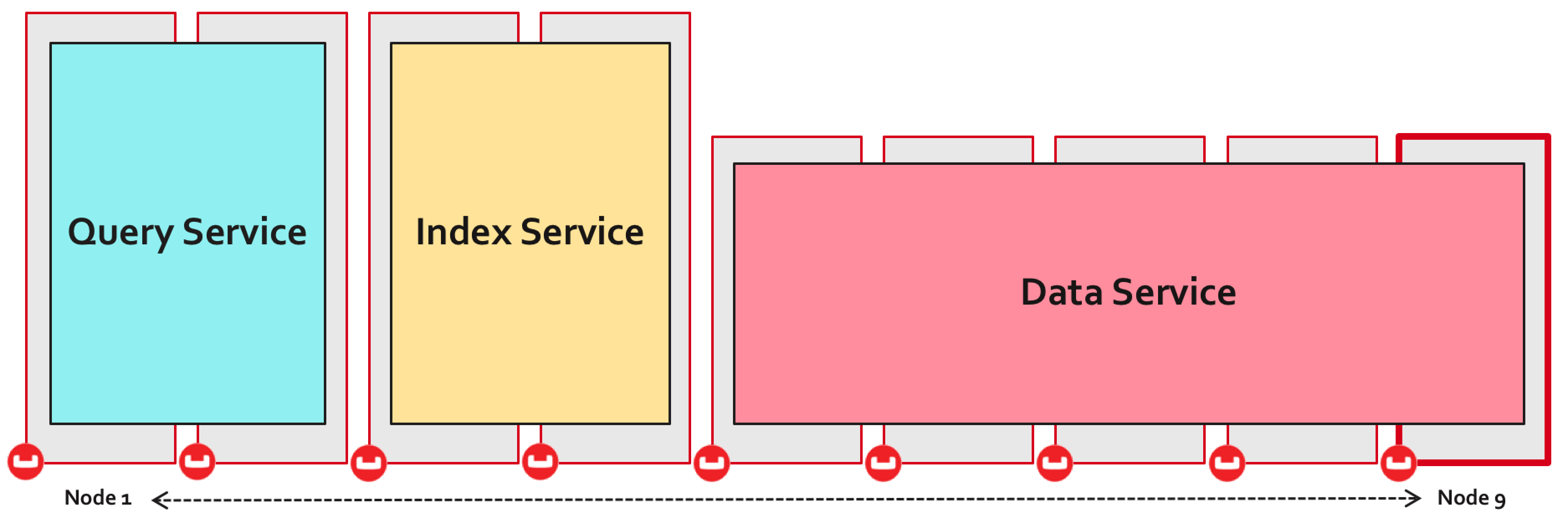
Let’s explore the differences between the services; For each service we’ll see why it is suited to scaling out or up. We’ll also explore the service’s specific hardware resource needs.
Data Service
Key value access in Couchbase is perfectly suited to scaling out because it is by design linearly/horizontally scalable; the more data service enabled servers you add to the cluster the greater the capacity to handle higher concurrent workloads and larger data volumes.
Every additional data service enabled server provides 1/n more hardware resources to improve scale and performance (where n is the number of data service enabled servers). That is to say, every additional data service server provides 1/n more network, 1/n more cpu, 1/n more RAM and 1/n more disk IO and disk capacity.
From a resource perspective, if the data service is primarily a key value store then it should be sized with the following guidelines (note - these guidelines are simplified, for detailed sizing guidelines see How Many Nodes? Part 1: An introduction to sizing a Couchbase Server cluster)
- enough RAM to cache its working set of active and replica data,
- enough disk IO to support its write workload (active and replica),
- enough disk capacity to support ~3x its total data volume (active and replica),
- minimum 4 CPU cores (I recommend 8 to 12 cores which allows you to enable other data service features such as XDCR and Views)
This means you can opt for very inexpensive commodity servers for your data service. If you want to support additional data service features such as view queries and cross data centre replication (XDCR) then you’ll need to consider investing in more than 4 CPU cores and additional RAM to cache view indexes in memory. Note Couchbase does not manage the cache for view indexes; instead it relies on the operating system cache. For more details about hardware sizing for views and XDCR please see: How Many Nodes? Part 3: Hardware considerations
Index service
The Index service is designed to create and maintain global secondary indexes. This means an entire index will reside on one physical machine. This is in stark contrast to View indexes which are local indexes distributed across all data service servers. Reading global secondary indexes is much faster than view indexes because there is no scatter/gather overhead. Not only is scan latency improved but so is throughput. With this in mind, it makes sense to scale the index service up with beefier boxes with greater CPU cores.
Indexing is a lot more CPU intensive compared to the data service (assuming its used primarily for key value) which again reinforces the notion of scaling up the index service. RAM should be sized to keep the entire index cached and disk capacity needs to support the persistence of the entire index.
Note that it is possible (and recommended for high availability) to provision multiple index enabled nodes. To gain high availability administrators can create the same indexes on multiple index service nodes. The Couchbase cluster will automatically load balance scans requests from SQL queries (from query service nodes) across these index enabled servers. This helps remove hot spots to a single GSI server (especially for a heavily utilized index) and provides high availability in the case of server failures.
In a nutshell I recommend at least 2 index service nodes with mirrored indexes for high availability.
Query service
The Query service can be much more CPU intensive than the typical data service that runs key value. Even if the data service is supporting views it’s CPU needs will generally be lower than the Query service. Executing SQL queries is a CPU intensive task, it involves parsing queries and fetching JSON documents, scanning documents, joining documents, ordering and projection.
The Query service also needs enough RAM to run these tasks - especially for the fetching of JSON documents from the data service for additional work. The query service is not designed to persist data - almost everything it does is transient in nature. Therefore, disk IO and disk storage needs are minimal when compared to the other services.
In conclusion, the query service is suited to scaling up as apposed to scaling out. With that said, just like the index service servers, it is possible and recommended for high availability to provision multiple query service nodes. Couchbase SDKs will automatically load balance SQL queries across the query servers. This also helps to improve performance and scale.
In a nutshell it is recommended to have at least 2 query service enabled servers for high availability.
MDS Summary
- Scaling the services independently allows you to pick the most suitable server spec and the ideal number of servers for each service.
- You can scale out the data service nodes using very low commodity servers that have low CPU cores but ample amounts of RAM and disk IO to handle the read/write workload.
- You can scale up the Index and Query servers with higher CPU cores, ample RAM and disks. You can also scale out the index and query services for high availability and to improve scale and performance.
- Finally its worth remembering that isolating each service removes any resource contention and issues between the services.
In the next blog we will dive deeper into the data service focusing primarily on how key value data is distributed and scaled.
blog comments powered by Disqus